Pdf Parsing
💬 Pdf Parsing
Unlock Actionable Insights from Unstructured Documents
PDF Parsing is the process of converting unstructured or semi-structured PDF content into structured, usable data.Our PDF parsing services utilize advanced techniques to ensure accurate data extraction. At Alluring Infotech, we specialize in transforming complex PDFs—such as invoices, contracts, reports, and statements—into searchable, analyzable formats using a blend of Python-based tools and AI-driven techniques.
Where It Helps:
- Contract Analysis: Automatically extract key clauses, obligations, and expiry dates from legal PDFs using our PDF parsing automation solutions.
- Invoice Processing: Parse line items, vendor details, and totals to streamline accounting workflows.
- Research Paper Summarization: Identify and extract abstracts, citations, and conclusions from lengthy academic documents.
How We Do It:
- Data Extraction Strategy: We identify the layout and semantics of PDFs to determine the best method—whether text-based, image-based, or a hybrid approach.
- Preprocessing & Cleaning: Extracted data is refined using tokenization, normalization, and noise filtering—ensuring it's ready for downstream automation or machine learning tasks.
- Custom Parsers & Models: For domain-specific documents, we build tailored parsers and train models to accurately extract and categorize relevant information.
Why It Matters:
- Improved Document Intelligence: Extract valuable insights from static documents to enable faster, smarter decision-making.
- Reduced Manual Labor: Automate repetitive review and data entry tasks with AI-powered extraction pipelines.
- Seamless AI Integration: Parsed data flows directly into AI systems for summarization, classification, or recommendation engines.
Tools & Frameworks:
- PyMuPDF / PDFMiner / PyPDF2: For low-level access to text and metadata within PDF files.
- Tesseract OCR + OpenCV: Ideal for image-based PDFs or scanned documents where traditional parsing doesn't work.
- spaCy / NLTK: Used for NLP tasks like named entity recognition (NER) on the extracted text.
- Pandas + Scikit-learn: To transform parsed data into ML-ready formats and build custom models.
- LangChain: Useful when chaining parsed PDF content into prompts or autonomous document agents.

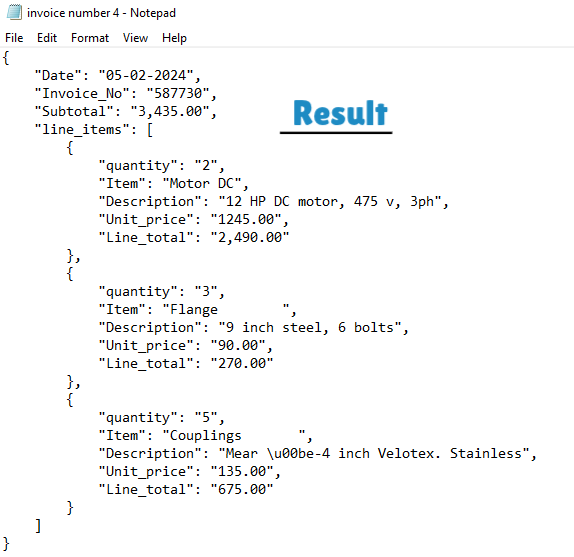
PDF table extracted and saved as JSON using Python
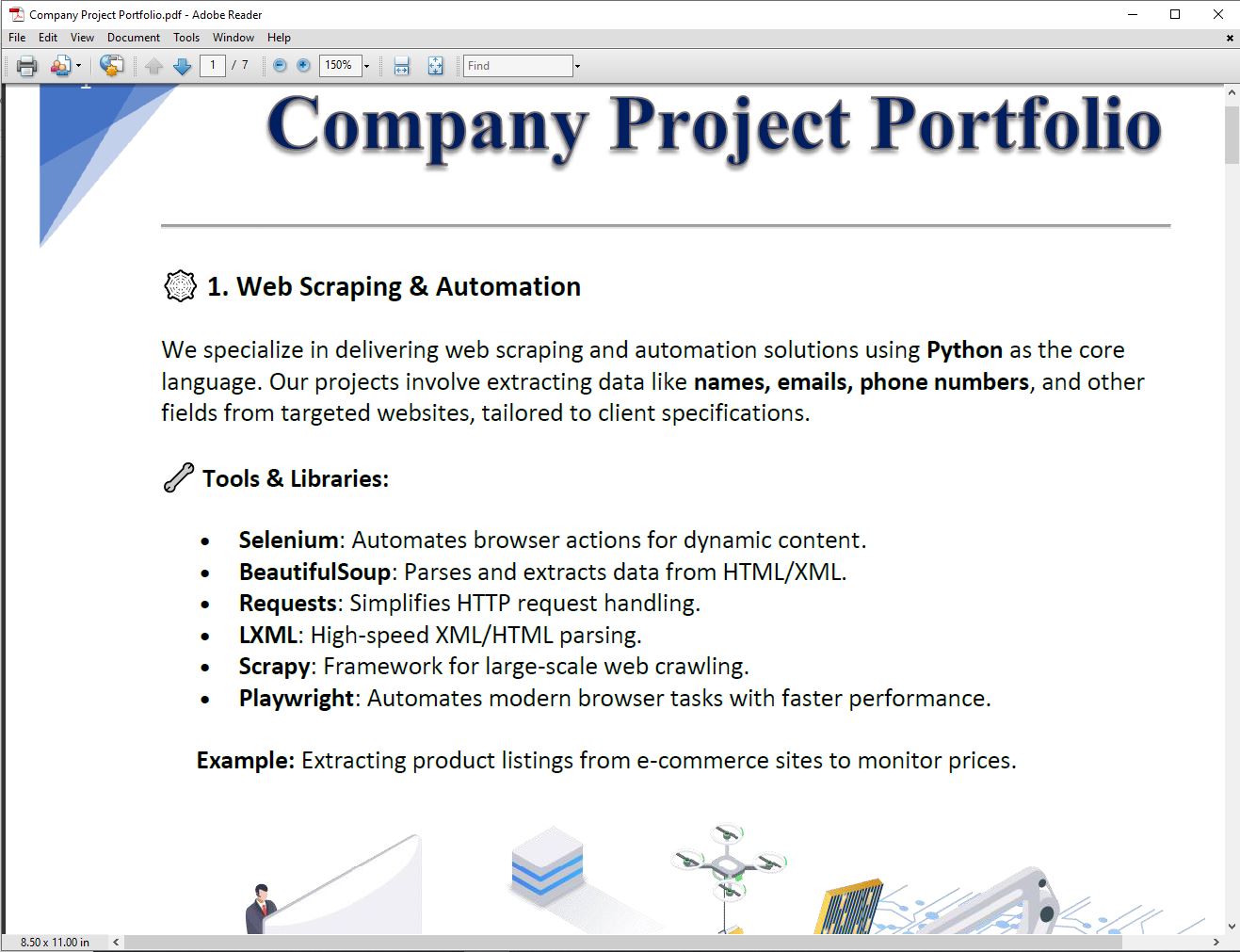
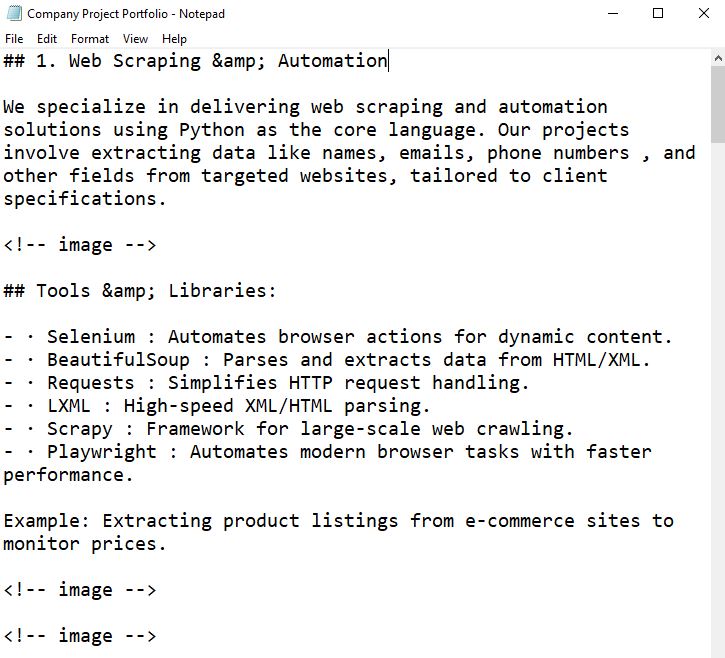
PDF text and images extracted and saved via Python










Get In Touch
D-270, Phase 8B, Industrial
Area, SAS Nagar, Punjab 140307
+91 96030-00071
Explore
Quick Link
2026 © Alluring Infotech Solutions. All Rights Reserved.